REDSearcher: A Scalable and Cost-Efficient
Framework for Long-Horizon Search Agents
*Equal Contribution
†Project Leader
✉Corresponding Author
🛠 Scalable task synthesis via graph-structured reasoning with topological complexity control
🚀 Cost-efficient training via mid-training of core search-agent subskills
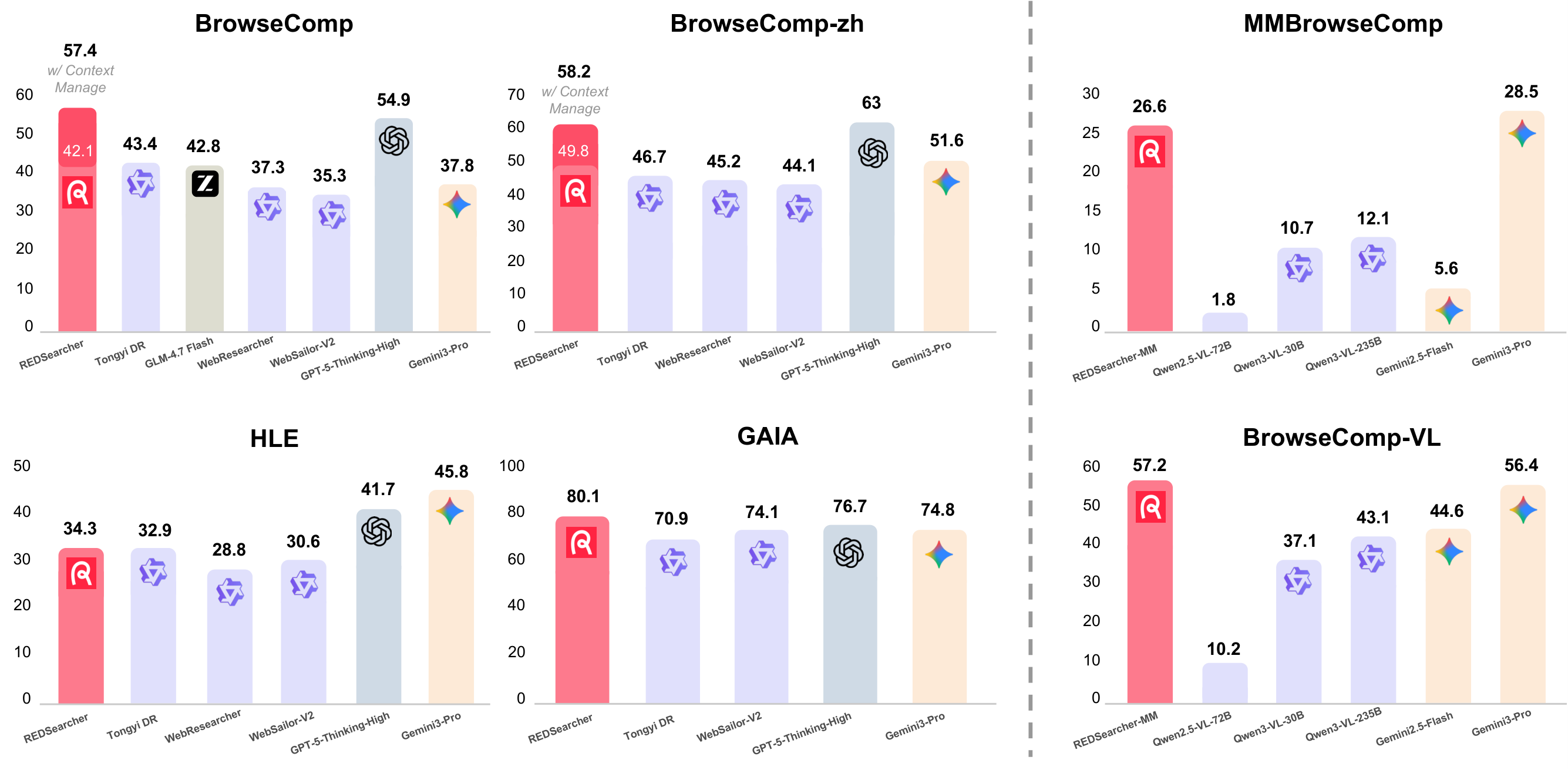
🏆 SOTA performance across both text-only and multimodal benchmarks